Braintrust comes up in nearly every observability conversation, so here is the direct answer. If you are evaluating AI observability platforms today, Braintrust is likely on your shortlist alongside Laminar. Both cover tracing, evaluations, and datasets. Both have polished UIs and serious engineering behind them. But for teams building production-grade AI agents, we believe Laminar is the stronger foundation — and we think the reasons matter.
This is not a neutral comparison. It is honest and practical, and it is biased toward Laminar because we built it around agent reliability, real-time debugging, and deep data access. If you want a batteries-included eval platform with a built-in AI proxy, Braintrust may be a fit. If observability and debugging are the center of your stack, Laminar wins.
There is a structural difference that deserves attention up front: Laminar is fully open source. Braintrust is not. For many teams, that distinction alone shapes the decision.
Short Answer
- Trust and control: Laminar is fully open source with free self-hosting. Braintrust is closed source, with self-hosting on Enterprise only and a hybrid control/data plane.
- Observability depth: Laminar prioritizes real-time traces, full-text search, and browser session replay. Braintrust has strong tracing but is eval-first.
- Data access: Laminar is SQL-native in product. Braintrust is SDK/API-first with in-platform querying.
- Evaluation workflow: Braintrust centers evaluation with CI/CD integration and experiment comparison. Laminar treats evals as an extension of observability.
- Pricing model: Laminar prices by data volume and keeps self-hosting free. Braintrust bundles more platform features and charges accordingly.
If your agents are already in production — especially multi-step, tool-heavy agents — Laminar's bias aligns with your day-to-day reality.
| Laminar | Braintrust | |
|---|---|---|
| Primary bias | Real-time agent observability | Evaluation lifecycle management |
| Open source | Yes — fully open source, self-host freely | No — closed source, self-hosting on Enterprise only |
| Trace depth | Tree/timeline explorer for complex agents | Structured trace viewer with span drill-down |
| Data access | SQL-native editor in product | SDK/API-centric access with in-platform querying |
| Best fit | Production agents with complex traces | Eval-heavy teams iterating on prompt quality |
Trust and Control: Open Source vs Closed Source
This is the biggest structural difference between the two platforms and it shapes everything downstream.
Laminar is fully open source. You can clone the repo, run docker compose up -d, and have the entire stack — tracing, evals, datasets, UI — running locally in minutes. You can inspect the code, modify it, contribute to it, and self-host it on your own infrastructure with zero licensing fees. There is no feature gating between self-hosted and cloud. The platform you run locally is the same platform we run in production.
Braintrust is closed source. The core platform, including the database engine (Brainstore), UI, and evaluation runtime, is proprietary. Self-hosting is available only on the Enterprise plan, and even then it operates as a hybrid model: the control plane remains in Braintrust's cloud while you run the data plane in your infrastructure. The AI proxy is open source under MIT, but the proxy is a small slice of the platform.
For teams with data residency requirements, security constraints, or a preference for vendor independence, this distinction is not abstract. It determines whether you can audit the code that handles your production data, whether you can run the system behind your firewall without a commercial agreement, and whether you can fork and extend the platform if your needs diverge from the vendor's roadmap.
Observability Depth: Real-Time and Replay
Braintrust does a solid job capturing traces, tool calls, latency, and cost. Its trace viewer lets you expand span trees and inspect inputs and outputs. It is a reliable tracing tool, especially when paired with its evaluation workflows.
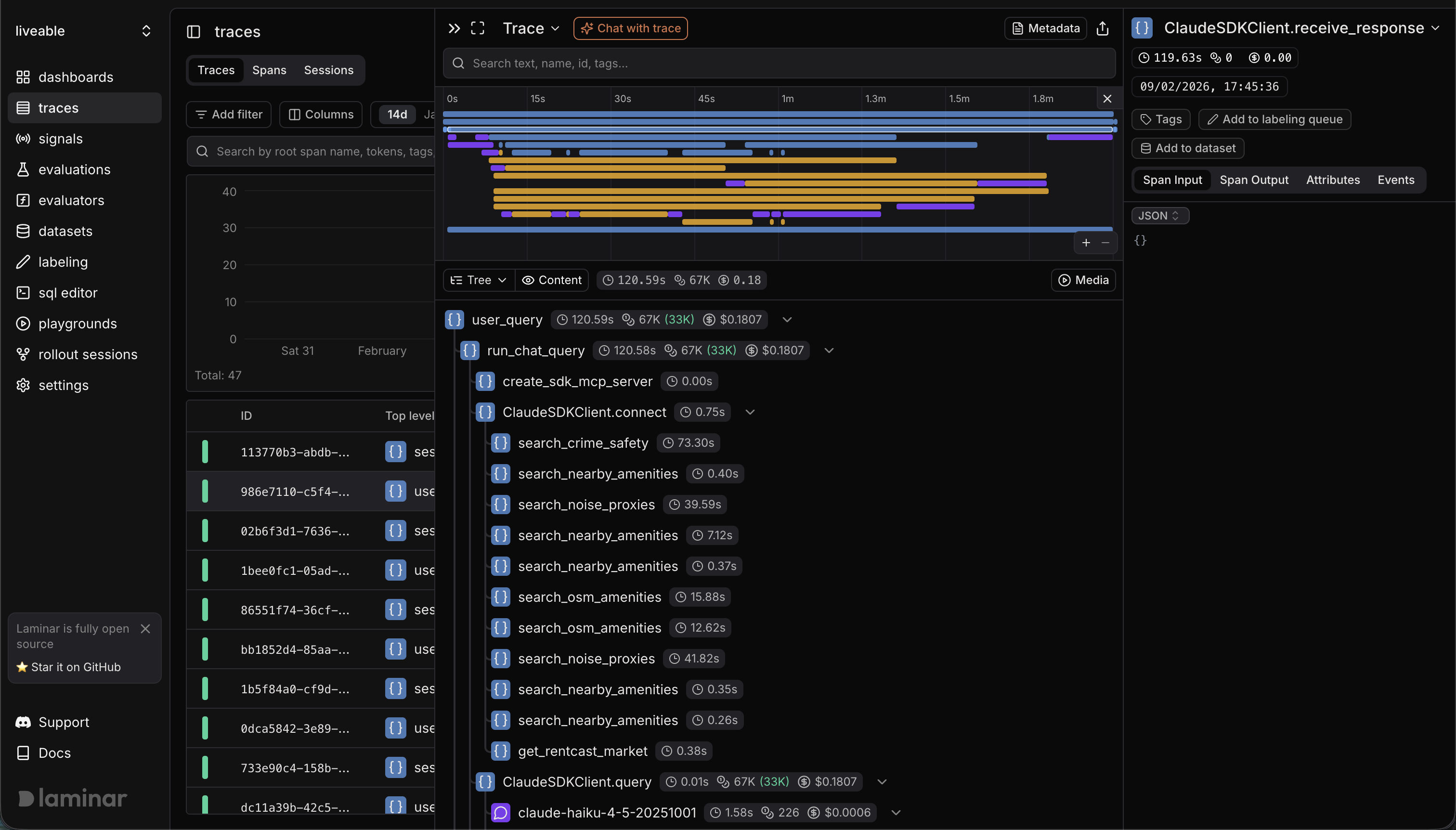
Laminar goes further because it is designed for complex, multi-step agents:
- Real-time trace viewing for long-running agents — you see spans as they happen, not after the run completes
- Full-text search over spans, making it easy to find specific errors or outputs across massive datasets
- Browser session replay synchronized with agent traces — when you are debugging browser agents, you can watch exactly what the agent saw at each step
- A trace viewer built for complex agent trees, not just single prompt/response pairs
- OTel-native ingestion, which fits naturally into existing observability pipelines without requiring a proprietary SDK on the critical path
Braintrust has invested heavily in Brainstore, its custom database for AI traces, which is built for fast queries at scale. That is real engineering. But the observability surface area — what you can see and how you navigate it — is where Laminar differentiates. If you are debugging multi-step agents that call tools, spawn subagents, and run for minutes, trace depth and real-time visibility are not optional. They are your core workflow.
Data Access: SQL-Native and Built In
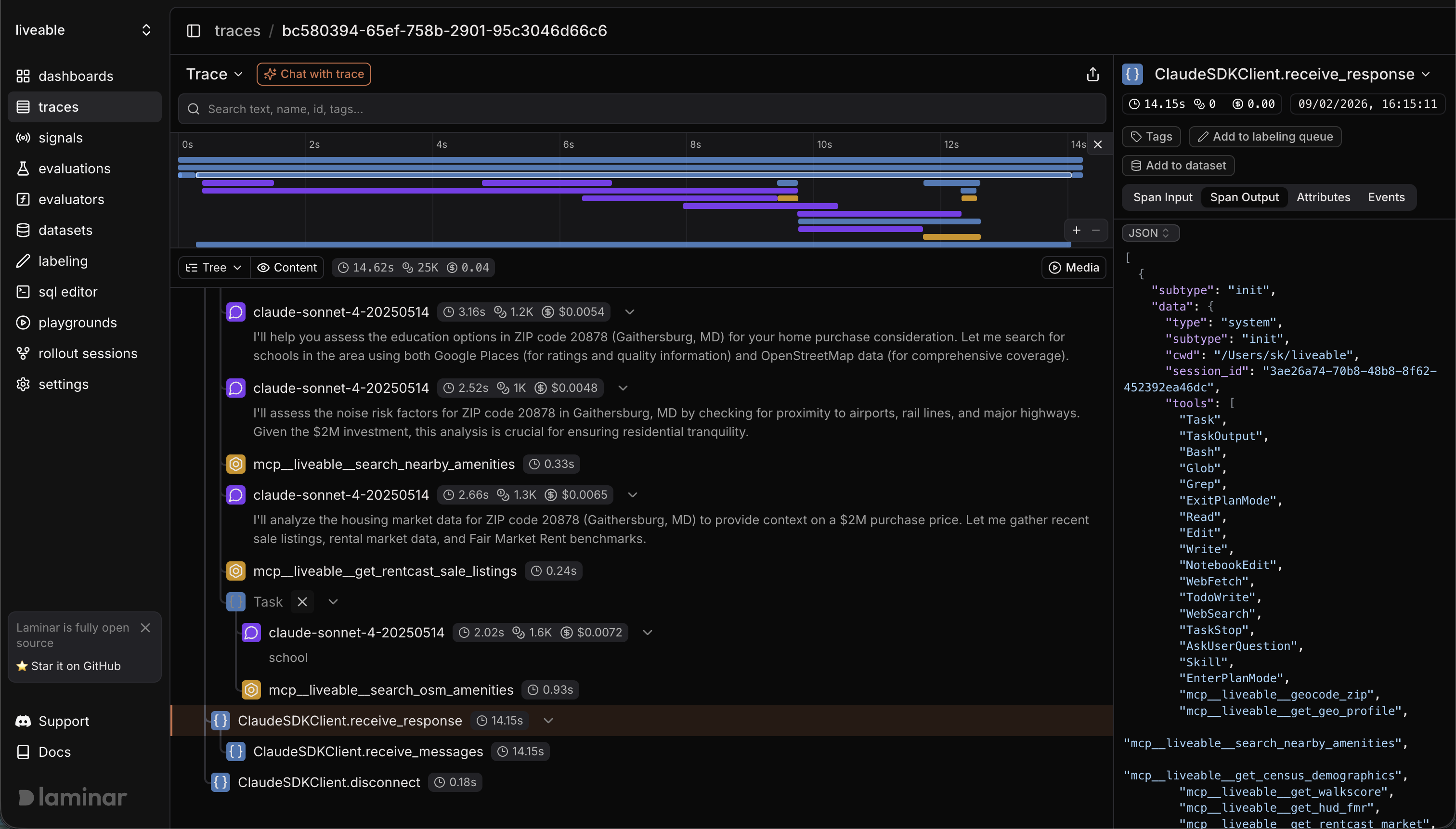
Laminar includes a built-in SQL editor that gives direct access to traces, spans, events, tags, and datasets. This changes the development loop:
- You can answer "why did this fail?" with one query
- You can build custom metrics without waiting for product features
- You can generate datasets directly from production traces
Braintrust supports querying through its SDK and API, and its UI includes filtering and search capabilities powered by Brainstore. But Laminar's SQL-first approach makes analysis immediate and interactive — you write a query, get an answer, and move on. That matters when your agent fails at 2 a.m. and you need to understand the pattern, not write a script.
Signals: Ask New Questions of Old Traces
Agents are messy. The failure pattern you care about today might not even exist in your dashboards. Laminar's Signals let you define a question once (prompt + schema), then run it across both new and historical traces.
That means you can:
- Detect specific failure modes as they happen (and alert on them)
- Backfill months of traces to validate a hypothesis
- Turn production trace history into labeled datasets without writing scripts
Braintrust has its own approach here with Loop, an AI assistant that analyzes logs and surfaces insights through natural language queries. Loop is a strong product idea — you describe what you want and it generates scorers, datasets, and prompt suggestions. But Loop operates within Braintrust's closed platform. Signals operate on top of your trace data, which you own and can query however you want.
UX: Trace-First vs Eval-First
Braintrust's UX is polished, especially around evaluation workflows. The Playground lets PMs and engineers iterate on prompts side by side. Experiment comparison views make it easy to see what changed between runs. The CI/CD integration with GitHub Actions means eval results appear on every pull request. This is a genuine strength.
Laminar's UX is optimized for trace navigation and debugging at scale:
- Multi-view trace exploration (tree/timeline/reader)
- Fast traversal across large traces
- Clear cost and token visibility at the span level
- Browser session replay synchronized with traces
- AI-powered trace summarization and debugging
In practice, this means Laminar is the faster tool when you are trying to understand what an agent actually did and why it failed. Braintrust is the faster tool when you are trying to compare two prompt variants across a golden dataset. Both matter — but for teams operating agents in production, the debugging path gets used far more often.
| UX Area | Laminar | Braintrust |
|---|---|---|
| Trace navigation | Tree/timeline/reader with fast traversal | Trace viewer with span drill-down |
| Browser agents | Session replay synced with traces | No browser session replay |
| Debug speed | Optimized for large, nested traces | Best when tied to eval iteration |
| Experiment comparison | Evaluations with dataset support | Side-by-side experiment diffing with CI/CD gates |
Evaluations and Datasets: Both Strong, Different Philosophy
Both platforms support evaluation workflows and datasets. The difference is philosophical.
Braintrust treats evaluation as the centerpiece of the AI development workflow. The idea is that you define what good looks like, run experiments systematically, and gate releases on eval results. This is a sound approach and it has worked well for teams like Notion and Zapier. The Playground, experiment comparison, CI/CD integration, and Loop all reinforce this loop.
Laminar treats datasets, annotation, and evals as extensions of observability rather than a separate workflow. You can go from a failed trace to a curated dataset and then back into evals without switching contexts. Online evaluations trigger LLM-as-a-judge or Python script evaluators on each received span. The cycle is: observe, detect, label, evaluate, improve — all in one place.
Neither approach is wrong. But if your primary pain is "my agent broke in production and I need to understand why, fast," Laminar's observability-first approach gets you to the answer faster. If your primary pain is "I need to systematically compare prompt variants before shipping," Braintrust's eval-first approach is purpose-built for that.
Pricing Model: Simplicity vs Feature Bundling
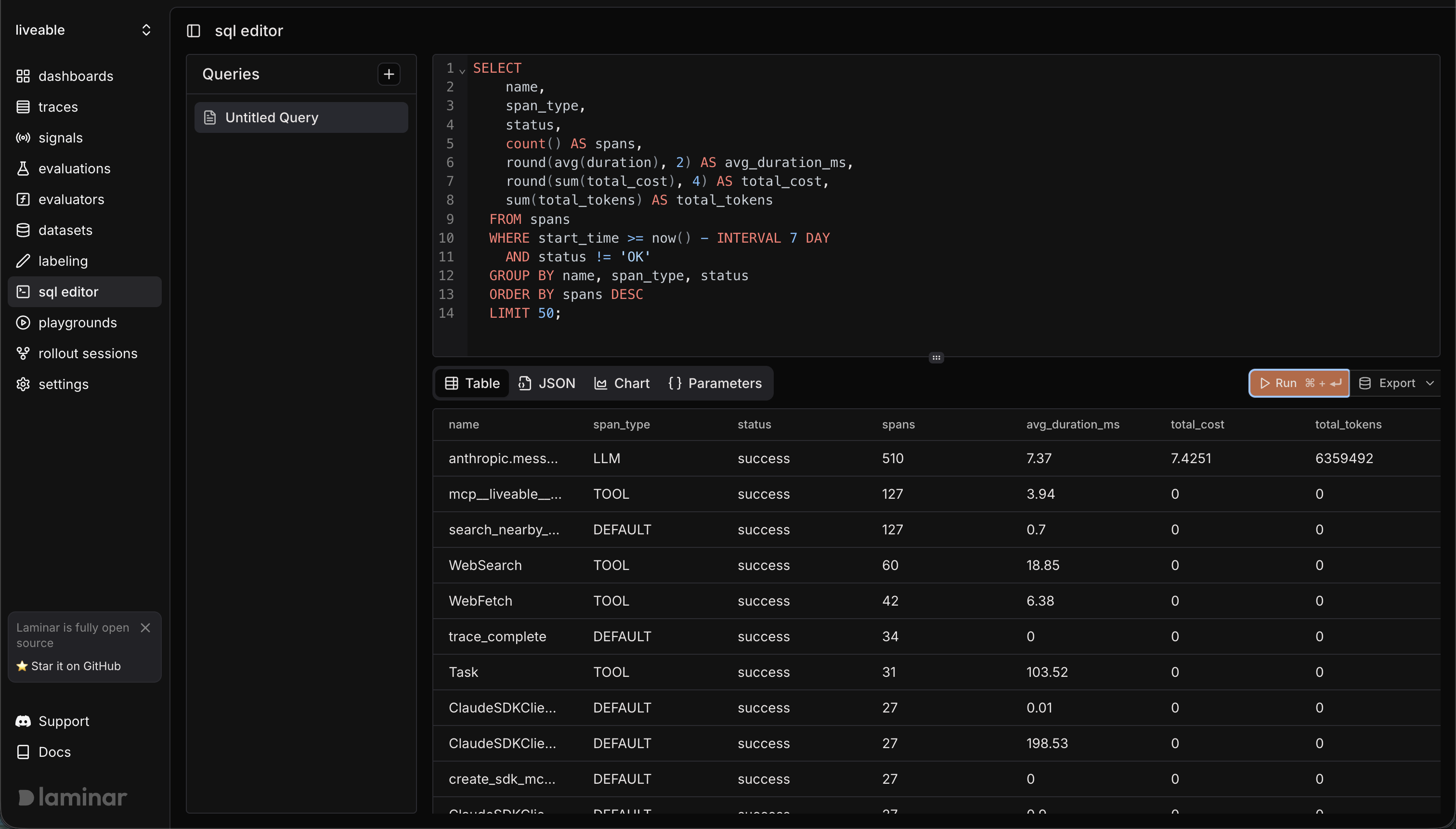
Braintrust offers a generous free tier (1M spans, 10k scores, unlimited users) and a Pro plan at $249/month. Self-hosting is only available on the Enterprise plan with custom pricing. The Pro plan includes unlimited spans but charges per GB of processed data ($3/GB) and per 1k scores ($1.50/1k) above the base allotment.
Laminar starts free (1GB data, 15-day retention) with a Hobby tier at $25/month (2GB, 30-day retention) and a Pro tier that scales with data size. Self-hosting is free at every tier — you can run the full platform without paying anything.
The pricing philosophies differ: Braintrust bundles more into the platform (AI proxy, CI/CD, Loop) and charges accordingly. Laminar prices by data ingested and gives you the entire open-source platform to run yourself. For teams that want to own their infrastructure and pay only for what they use, Laminar's model is more predictable and more transparent.
Architecture: Designed for Speed
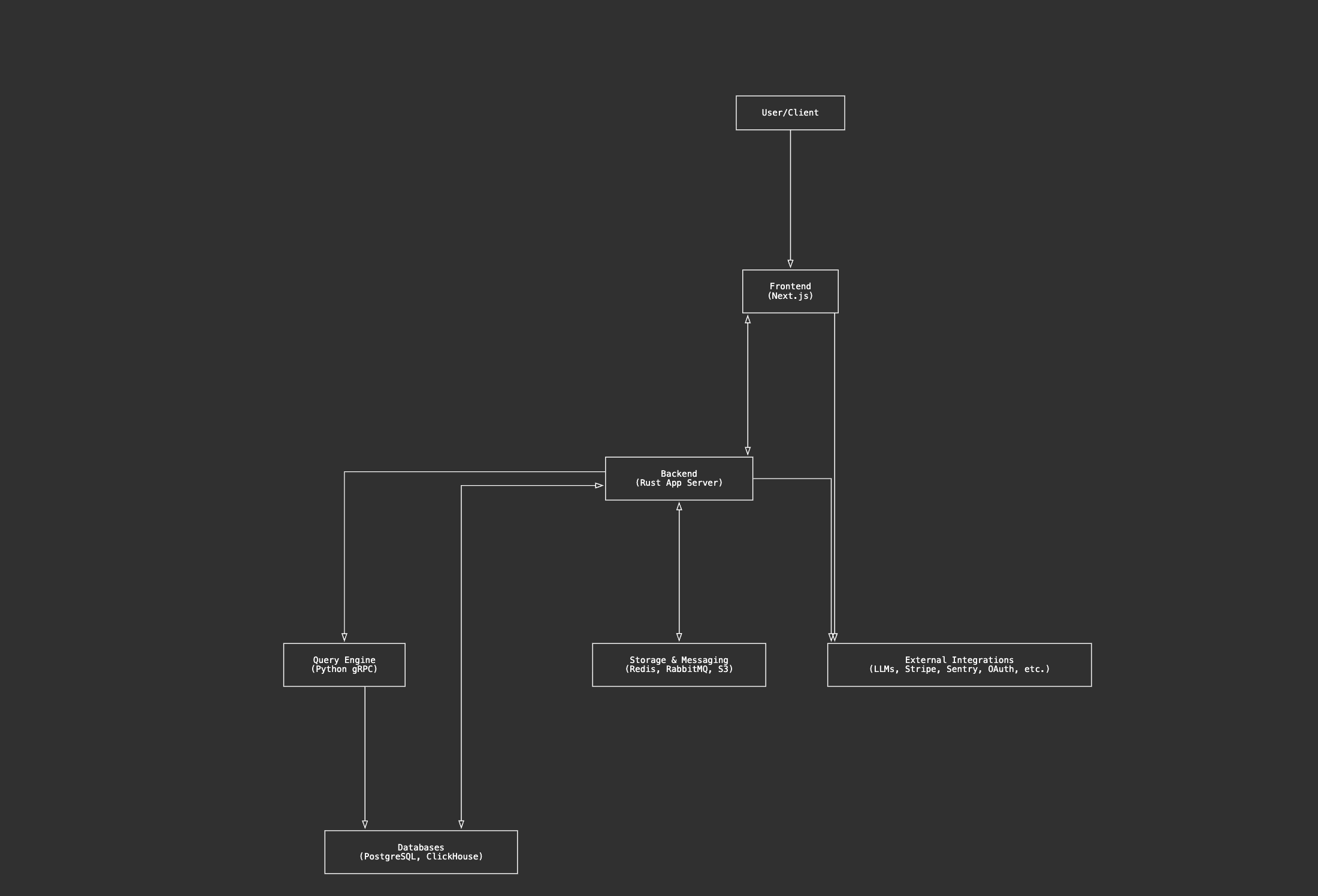
Laminar's stack is tuned for high-throughput agent observability:
- Rust backend for performance
- gRPC ingestion for low-overhead trace collection
- ClickHouse for analytics
- Postgres for transactional state
- RabbitMQ for async processing
- OpenTelemetry-native from the ground up
Braintrust has invested heavily in its own approach with Brainstore, a custom database built specifically for AI traces. Brainstore uses object storage, per-customer partitioning, and Tantivy for search. It is fast — Braintrust claims 80x improvement over traditional data warehouses. The architecture is serious.
Both stacks are production-grade. The difference is that Laminar's architecture is open and inspectable. You can read the code, understand the tradeoffs, and modify the system if you need to. Braintrust's architecture is a black box unless you are on the Enterprise plan with hybrid deployment.
The AI Proxy: Nice to Have, Not Essential
Braintrust includes an AI proxy — an OpenAI-compatible API that routes requests to multiple model providers with built-in caching and automatic trace logging. The proxy is open source (MIT) and can be used independently of the platform. It is a convenience layer that some teams find valuable.
Laminar does not include an AI proxy, and that is intentional. We believe the observability layer should be decoupled from the model routing layer. If you want a proxy, tools like OpenRouter or LiteLLM are purpose-built for that job and integrate cleanly with Laminar's OTel-native tracing. Bundling a proxy into the observability platform creates coupling that most production teams eventually want to avoid.
The Practical Choice
Use Braintrust if:
- You want a batteries-included platform with eval, proxy, and CI/CD integration out of the box
- You are primarily iterating on prompt quality and running systematic experiments
- You do not need open-source access or unrestricted self-hosting
- You want an AI assistant (Loop) that generates scorers and datasets from natural language
Choose Laminar if:
- You need open-source observability with full self-hosting freedom
- You are operating multi-step agents in production (or getting there fast)
- You need real-time trace visibility and browser session replay
- You want SQL-native access to telemetry
- You care about speed, debugging depth, and vendor independence
That second list is the world we live in. It is why we built Laminar, and why we believe it is the better platform for serious production agent work.
Don't Just Take My Word for It
If you want to see Laminar in action, start by tracing a single agent workflow. It takes minutes to set up, and the moment you open your first trace tree, the difference becomes obvious.
git clone https://github.com/lmnr-ai/lmnr
cd lmnr
docker compose up -d
Or just sign up at laminar.sh and start tracing immediately.
If you are evaluating observability platforms right now, we would love to help you compare against your exact use case. Reach out and we will show you what Laminar looks like on real production data.
