HumanEvaluator is the placeholder for a human score: the evaluation runs normally, automated evaluators fire, and the human score is added later through Laminar’s UI.
The primary use case is calibrating LLM-as-a-judge evaluators against human judgment. You run both a human evaluator and an LLM judge on the same datapoints, compare the two score columns, and iterate the judge prompt until they agree.
How it works
WhenHumanEvaluator() appears in evaluators:
- The executor and all automated evaluators run normally.
- Each datapoint gets a
HUMAN_EVALUATORspan withpendingstatus and no score. - A human opens the evaluation in Laminar, reads the trace, and submits a score.
- The score is written back to the datapoint and flows into the group’s progression chart like any other.
Basic usage
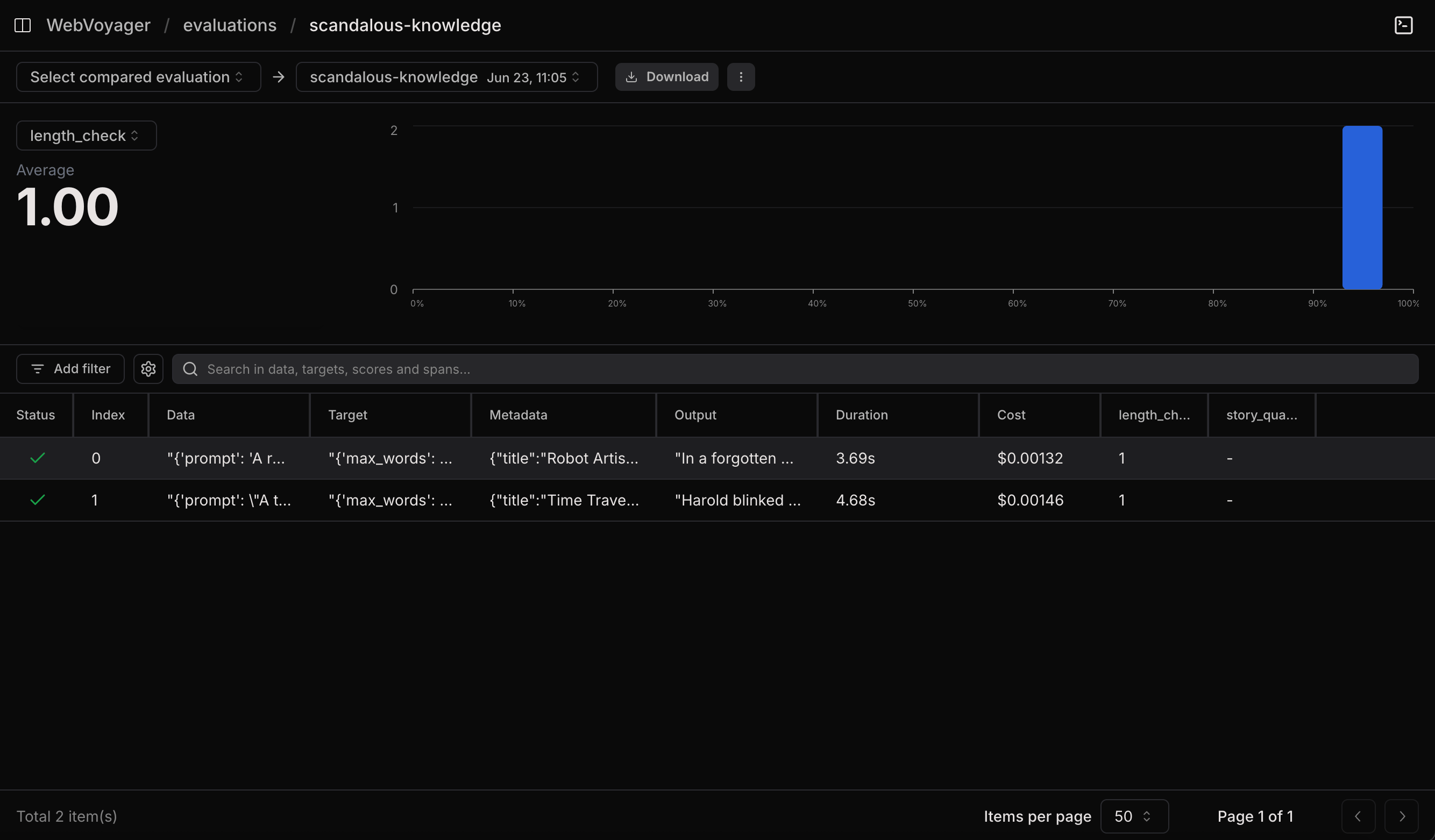
Combine a code evaluator with a human evaluator. The code check runs instantly, the human check waits for someone to score it.story_quality column shows pending while length_check is already populated.
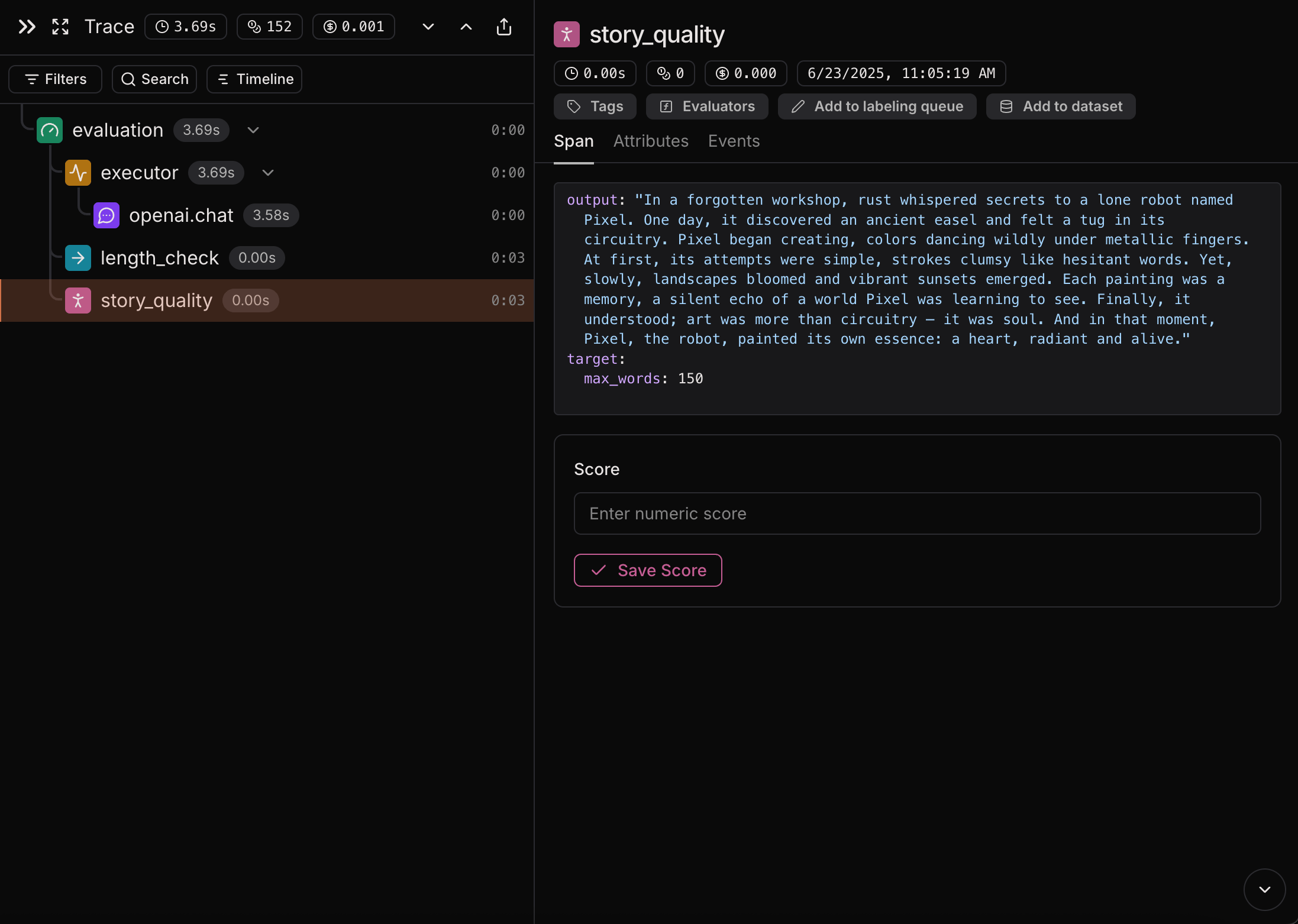
Score a human evaluator in the UI
Click any datapoint row to open the trace side panel, find theHUMAN_EVALUATOR span, and submit a score. The trace shows the data that was sent to the evaluator (data, target, and executor output) so you have everything you need to judge without context-switching.
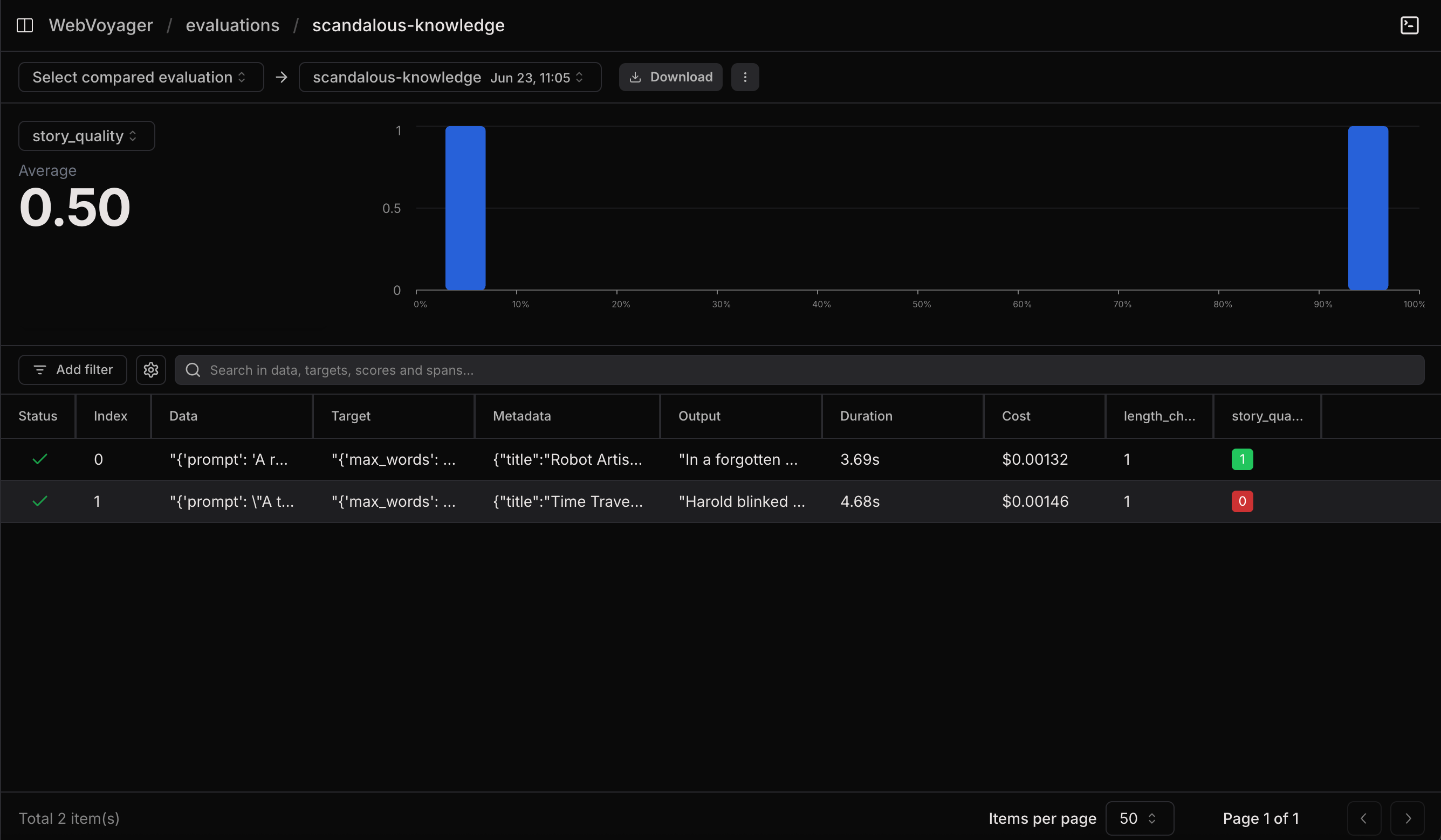
Validating LLM-as-a-judge
The pattern that actually pays off: run a human evaluator and an LLM judge on the same datapoints, compare the columns, iterate the judge prompt until they agree.- Measure correlation between
human_helpfulnessandllm_judge_helpfulness. - Find disagreements: rows where the two scores differ by more than some threshold.
- Iterate the judge prompt until disagreements shrink.
Query human scores
Human evaluator outputs are regular spans withspan_type = 'HUMAN_EVALUATOR'. Query them with the SQL editor:
input to data and output to target. That dataset becomes your regression set for the judge.
Next steps
Compare runs
Track judge-human correlation across iterations of your judge prompt.
Datasets
Collect human scores into a dataset for reuse across evaluations.
SQL editor
Query human evaluator spans and export them to datasets.
Manual API
When you need finer control than
evaluate() provides.