evaluate() is the right entry point for 95% of cases. For the other 5% (wiring evaluations into an existing pipeline, streaming datapoints from a long-running job, scoring production traffic after the fact) use the lower-level LaminarClient.evals API.
When to use this
Reach for the manual API when you need to:- Create an evaluation now and append datapoints to it over hours or days, as work completes.
- Register a datapoint in the UI before the executor runs, so a row is visible while the run is still in progress.
- Run the executor in one process and write scores from another (for example, an async judge that posts results back later).
- Score production traces without re-running the call: save the executor output and scores against a new datapoint.
evaluate().
The three-phase pattern
The manual API is designed around three distinct moments in an evaluation’s lifecycle. Call them in order:- Create the evaluation with
create_evaluation/create. Returns aneval_id. Do this once per run. - Pre-register each datapoint with
create_datapoint. Returns adatapoint_id. A row appears in the UI immediately, even though the executor hasn’t run yet. - Update the datapoint with
update_datapoint: link it to a trace, then (once the executor and evaluators finish) write the executor output and scores.
Setup
Build executor and evaluator spans
Wrap the executor and each evaluator inobserve() with the matching spanType. The evaluation UI uses EXECUTOR and EVALUATOR to know which spans hold the input, output, and score for each row.
Create the evaluation and datapoints
Open the evaluation up front, then loop over the test data. For each row, pre-register the datapoint, run the executor inside anEVALUATION span, and write scores back once the evaluators finish.
The two SDKs link traces to datapoints in slightly different places. TypeScript accepts
traceId on createDatapoint only, so call it from inside the EVALUATION span and pass Laminar.getTraceId() there. Python’s update_datapoint accepts trace_id, so you can register the datapoint before the span opens and link the trace once it’s running. The Python pattern is what you want when the row needs to be visible before you know which trace will own it.Decoupling the executor from the scorer
Becauseupdate_datapoint can be called any time after create_datapoint, executor and scorer can live in different processes. A common shape:
- A worker runs the agent, produces a trace, and calls
update_datapointwithexecutor_outputand an emptyscores={}dict. - A judge process reads
executor_outputfrom the dataset or from the agent’s output store, scores it, and callsupdate_datapointagain with the filled-inscores.
datapoint_id. The UI updates in place each time.
Backfilling without running the executor
For pure backfills (rows you already have outputs and scores for, no live executor), loopcreate_datapoint + update_datapoint over the pre-scored rows:
EVALUATION span is opened, so no trace is attached. The row shows data, target, executor_output, and scores, which is enough for the list view, progression chart, and side-by-side comparison. Use this when you want the numbers in Laminar but don’t need per-row transcript drill-down.
Result
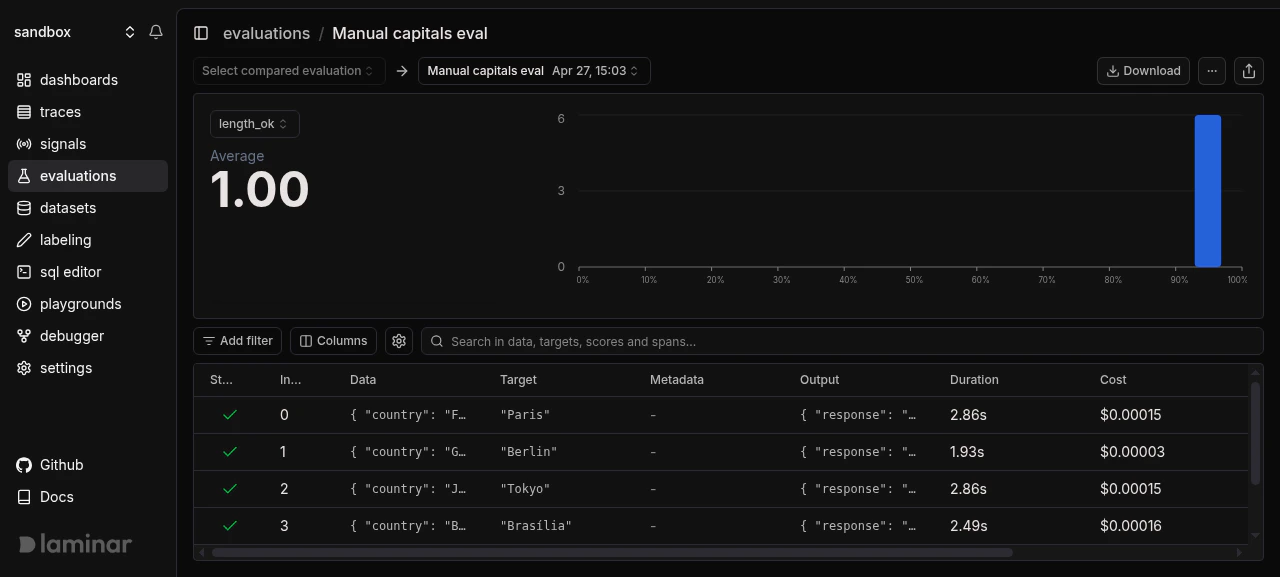
Manual evaluations show up in the same evaluations list, progression chart, and comparison UI asevaluate() runs. Groups, per-datapoint deltas, and CSV export all work the same way.
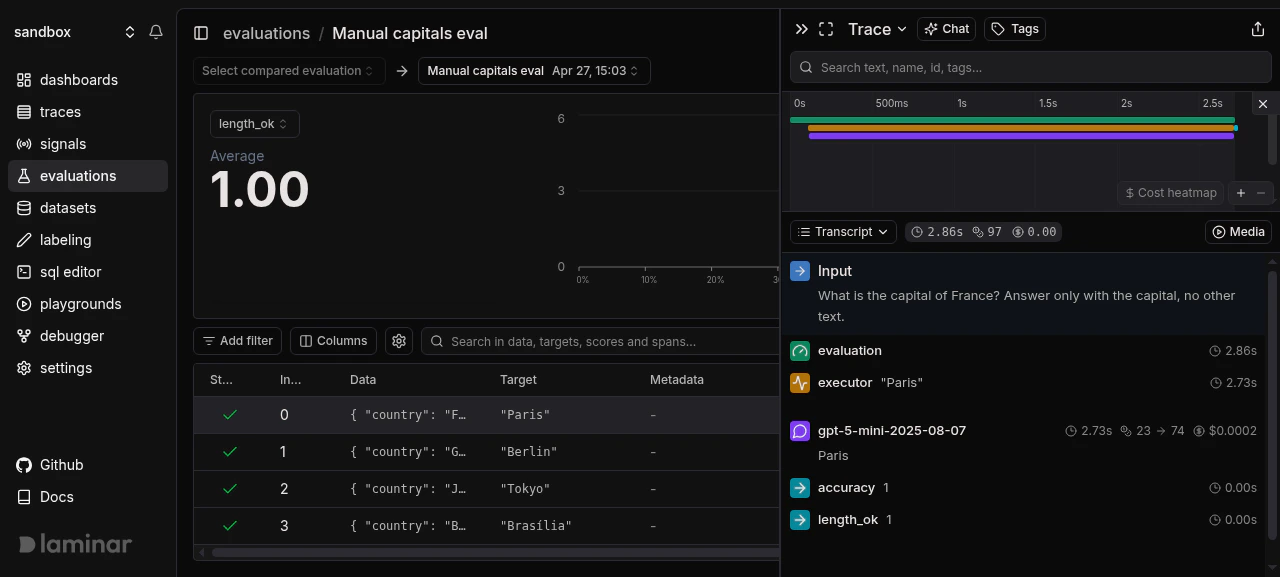
Manual evaluation detail page. Progression chart and datapoint table match what evaluate() produces
EVALUATION root, EXECUTOR, and EVALUATOR nesting you’d expect from evaluate().
One datapoint's transcript: EVALUATION root, executor, the gpt-5-mini call, and accuracy / length_ok scores
Next steps
Quickstart
The high-level
evaluate() API, which is the right starting point for most cases.Compare runs
Group manual runs so you can compare them like any other evaluation.
Concepts
The datapoint / executor / evaluator / group model the manual API maps onto.
SDK reference
Full parameters for
LaminarClient.evals methods.