Prerequisites
To get the project API key, go to the Laminar dashboard, click the project settings, and generate a project API key. This is available both in the cloud and in the self-hosted version of Laminar. Specify the key atLaminar initialization. If not specified,
Laminar will look for the key in the LMNR_PROJECT_API_KEY environment variable.
Install the SDK and set your API key:
- TypeScript
- Python
Write the evaluation
The file below has all four parts of an evaluation: a list of datapoints, an executor that calls the LLM, two evaluators (one for correctness, one for output length), and a name so you can find it later.- TypeScript
- Python
capitals-eval.ts
Pass
instrumentModules so Laminar instruments the OpenAI client. Without it, LLM calls still run but they won’t appear as spans on the executor trace.- The executor’s type on
datamatches the shape of each datapoint’sdatafield. Evaluators take the executor’s return as their first argument andtargetas their second. - Evaluators return a number. You can also return a dict if one evaluator produces multiple score dimensions (for example
{ "precision": 0.9, "recall": 0.8 }). groupName/group_nameties related runs together. Keep it stable across prompt and model changes so Laminar can compare runs and draw a progression chart.- No
Laminar.initialize()needed.evaluate()initializes Laminar on first call.
Run it
You have two options. Pick whichever fits your workflow.As a script
- TypeScript
- Python
Via the CLI
The CLI discovers evaluation files in anevals/ directory and runs them all in one pass. Use this in CI or when you want to run a suite.
- TypeScript
- Python
Files named
*.eval.ts or *.eval.js under evals/ are picked up automatically:Read the results
Every datapoint becomes one trace. Every trace gets one score per evaluator. The evaluation page is a split view: the datapoint table on the left, the trace for the selected row on the right. Pick a score dimension in the top-left dropdown to see its aggregate for the run; for non-binary scores an aggregation picker appears next to it (Average by default; Sum, Min, Max, Median, and percentiles). Score chips above the trace show every score for the selected datapoint.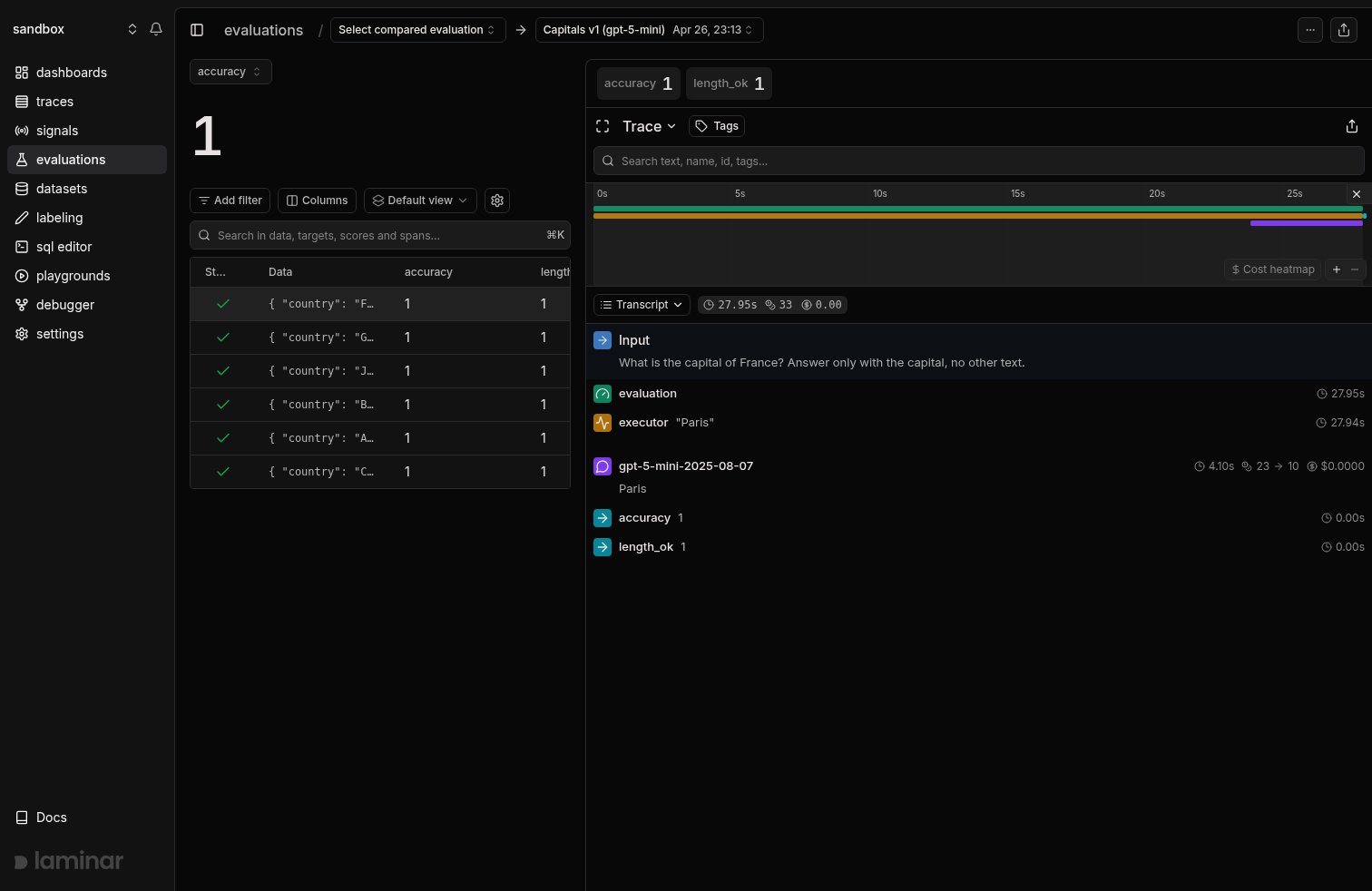
One evaluation run: datapoint table on the left with a score per evaluator, the selected datapoint's trace on the right. The transcript shows the input, the executor span, the model call, and both evaluator scores
Change something and run it again
KeepgroupName the same and change the thing you want to test. The second run lands in the same group, and Laminar charts the average of every score dimension over time.
For example, change the prompt so the model returns a full explanatory sentence:
length_ok drops from 1.0 to 0.0 for every datapoint while accuracy stays at 1.0. That’s a regression you caught before production.
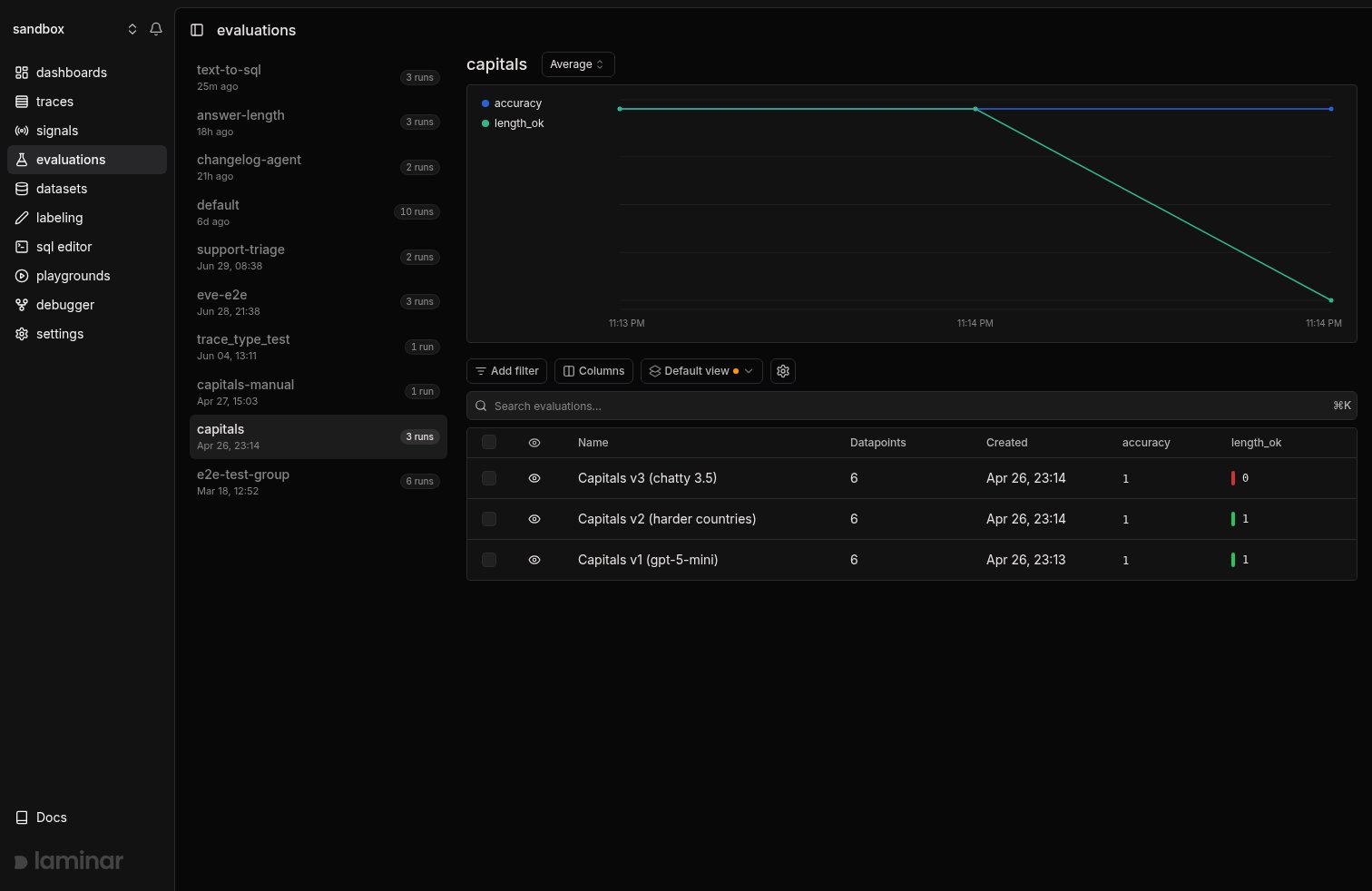
The capitals group after three runs. length_ok goes from 1.0 on v1 and v2 to 0.0 on v3 (the chatty prompt); accuracy stays flat
Add custom columns
In the evaluation results table, click Columns → Add column to create a computed column from SQL. This is useful for pulling fields out ofmetadata, data, target, or scores without changing your evaluation code.
Example: extract a model name from JSON metadata:
String or Float64) and save. The expression runs per row on evaluation_datapoints. For more JSON parsing functions, see the SQL editor.
Next steps
Concepts
The executor, evaluator, datapoint, and group model in detail.
Compare runs
Group runs, read the progression chart, diff side-by-side.
Datasets
Point
evaluate() at a Laminar dataset instead of a hardcoded list.Manual API
Lower-level control for pipelines where
evaluate() is too opinionated.